A computer program is said to learn from experience E with respect to some task T and some performance measure P, if its performance on T, as measured by P improves with experience E. - Tom Mitchell, 19981) In the case of Neko learning from datasets:
E is the collocation of colors and words in a database.
T is the clustering and re-clustering of colors with words.
P is the score of the clusters (how well-sorted they are).
 |
An example of k-means clustering |
2) In the case of Neko learning from people:
E is testing colors on different individuals.
T is returning a color, given some text.
P is the number of well-liked colors.
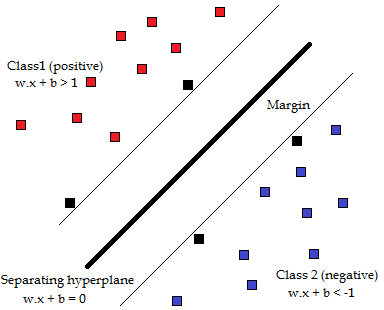 |
An example of a support vector machine |
The categorical names for each are that Case 1 is unsupervised clustering, and Case 2 is supervised classification. K-means is a likely algorithm for the former, and a support vector machine for the latter. Because order is meaningful (Orange is closer to Red than Yellow), color is a regression problem with continuously valued output. But there is a sense in which colors are discrete as well, so that's what I'm mulling over now.
No comments:
Post a Comment